第三十一章 Masktools与Mask生成
1. MaskedMerge
在日常做番中,后缀表达式主要用来处理 mask,也就是和本章介绍的 Masktools 相关的内容。
如字面意思,Masktools 指的是和 mask 相关的一系列函数,这些函数最初是 Avisynth 的一个滤镜。
而到了 VapourSynth,许多重要的 Masktools 函数直接集成到了 std 里。
mask 的核心是 std.MaskedMerge 函数,这是 std 里唯一一个函数名带有 mask 的函数。
在上一章里我们实现了 Merge 函数,它可以根据 weight 融合两个 clip。
Merge 中的 weight 是一个全局的常量,如果 weight 不是固定的,而是每个位置的像素都有一个独立的 weight,那么这些所有 weight 也构成一个 clip,这个 clip 就是一个 mask。
这样通过一个 mask 来进行 clip 的融合,就是 std.MaskedMerge(clipa, clipb, mask) 的功能。
从这个例子可以看出,std.Merge 与 std.MaskedMerge 的主要区别是,后者允许在画面不同区域施加不同的权重,这就是 mask 的含义。
通过 mask,我们可以进行一系列精细的操作,比如根据图像亮度调整降噪力度、根据线条和非线条分别进行 AA、deband 等,因此 mask 是一个非常重要的操作。
与前面课程学到的 rgvs.RemoveGrain/rgvs.Repair 类似,许多 Masktools 函数进行的是十分简单的运算。但是,实际应用中的一个困难是,人比较难把像素值与图像直接联系起来。
为了解决这个麻烦,一方面需要有一定的经验积累;另一方面,我们可以通过理解操作的一些性质,让我们更快得到我们想要的输出图像。
(1). MaskedMerge的使用
下面继续介绍 std.MaskedMerge 的用法。
从文档可以看到,std.MaskedMerge 的参数格式是 std.MaskedMerge(clip clipa, clip clipb, clip mask[, int[] planes, bint first_plane=0, bint premultiplied=0])。
前三个参数我们已经了解了。其中 mask 就是混合两个 clip 时的权重,在 mask 为浮点,也就是取值 0-1 的时候很好理解,这与 merge 中的 weight 含义相同。
使用整数 clip 作为 mask 时,比如使用 8bit,这时 mask 输入的取值是 [0-255]。
与浮点情况类似地,当 mask 数值为 0 的时候,输出等于 clipa;数值为 255 的时候,输出等于 clipb;当数值为中间值时,输出为 clipa 与 clipb 的对应加权混合。
第四个 planes 参数用来控制处理哪些平面。
第五个 first_plane,需要重点讲一下。
在默认情况下,MaskedMerge 是逐平面进行的,也就是计算第 i 个平面时采用 mask 的第 i 个平面作为权重。
然而在实际使用中,对于 YUV 格式,我们很少对 UV 单独生成 mask,一般习惯于复用 Y 的 mask 来处理 UV。
当指定 first_plane=True 时,将会使用 mask 的 Y 平面作为计算每个输出平面的权重。在必要时,比如 420 下采样时,滤镜会自动使用 bilinear 将 mask 缩放到对应的分辨率。
这一过程中,它不会考虑 chroma location,这在 MPEG2 这种非中心对齐的 subsampling 上自然会带来 chroma shift。
这里需要说明的是:
与直接处理画面不同,和 mask 相关处理是允许有一定误差的。
mask 数值上的改变 x,在输出图像上通常只会带来比 x 小得多的改变。
在整数 clip 的情况下,由于 round 的存在,mask 上小的数值变化甚至可能根本改变不了画面输出。
另外,生成 mask 时通常也会留有余量,一点微小的偏移通常不会改变结果。
因此,大多数情况下直接交由 MaskedMerge 处理缩放是可以接受的。
(当然也可以不用这个开关,自己 resize 修正这个问题。
MaskedMerge 的最后一个参数不用管,一般用不上。
2. Mask生成
介绍完 mask 会被怎么使用(通过 std.MaskedMerge),接下来介绍一些基础生成 mask 的方法。
mask 可以分成两类,分别是根据像素值直接得到的 mask,以及根据图像特征,比如通过边缘检测得到的 mask。
(1). 基于像素值的mask
我们知道,人眼对于暗场中的噪点比亮场中的更敏感。我们可以保留暗场中的噪点,削弱或去除亮场中的噪点。这样既能使输出画面看起来接近源,又能降低视频体积。
为了达到这一效果,最简单的想法是设定一个阈值:比如说,对于亮度小于等于 8-bit 数值 60 的像素,我们不进行降噪;对于亮度大于 60 的像素,进行降噪。
在 8bit 低码率处理中,我们做过类似的操作。
这可以通过 Binarize 滤镜实现。
luma_mask = core.std.Binarize(src, 60, planes=0)
std.Binarize 的参数格式是 std.Binarize(clip clip[, float[] threshold, float[] v0=0, float[] v1, int[] planes=[0, 1, 2]])。
这里的 threshold 就是前面提到的阈值。
三、四个参数,v0 和 v1 用来表示低于和高于阈值时的输出值,16-bit 下默认分别是 0 和 65535。
(当然可以用 Expr 实现 std.Binarize,它们只会有轻微的速度和内存占用区别:Expr 在浮点数下计算,std.Binarize 直接在整数算。
前面这种设计的一个问题是,降噪与不降噪的选择没有过渡,这样会让降噪后的图像突兀。
我们可以设计连续的 mask 来解决这个问题:比如,亮度低时不降噪;亮度增大时,降噪力度也随之增大。
最简单的,把 src 本身当成 mask 并加上 first_plane=True,就达到了这个效果。
当然也可以用其他各种方法生成这种连续 mask。
比如实际中常用 Expr 生成基于二次函数的 mask,在 8-bit 数值 64 附近降噪力度最小,两端的降噪力度增大。
mask = core.akarin.Expr(src16, "x 64 - 256 * 2 ** 5 *")
后续课程会进一步介绍这方面 mask 的设计。
(2). 基于边缘检测的mask
另一种常见的方式是通过图像特征,比如边缘检测来生成 mask。
在许多处理中我们有根据 edge/nonedge 分别处理的需要,对应的 mask 叫 edge mask。
在视频图像处理里有很多边缘检测算法,我们简单介绍一下最经典的两种。
Sobel算子
我们知道,边缘或者说线条是像素值快速突变的区域,因此可以通过变化率来检测边缘。
数学上,表示变化率的是导数。下图展示了一维情况下,图像和导数的情况。可以看到,在图像边缘处,导数很好地检测出图像变化的剧烈程度。
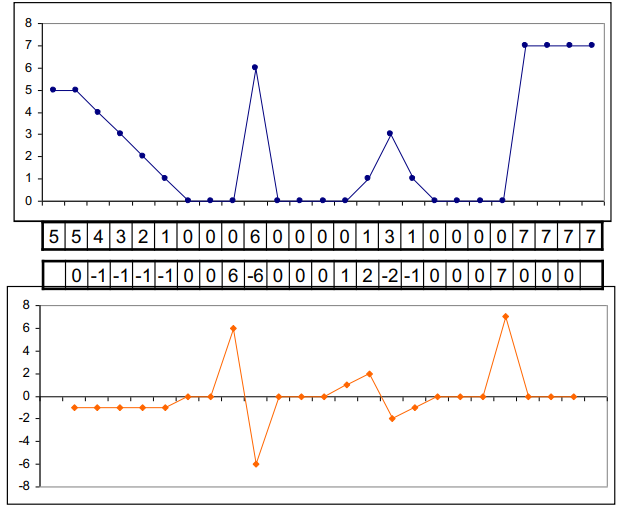
在二维空间上,类似的概念是梯度,梯度的模表示该点最大的变化率。因此我们使用图像上每个像素的梯度的模长,来衡量图像的变化程度。
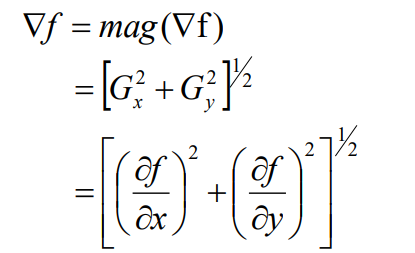
一般地,可以近似简化为:
在离散图像的情况下:
这里的 是一种概括性的表达,实际上也可以用 。
而在实践中,往往会使用邻域来进行计算,因此一阶导数的计算会有多种不同形式。
其中经过实践检验效果较好的一种计算方法如下,它利用了邻域的信息,并且强调了横竖正方向的贡献。
上述操作可以分解为两个矩阵,称为 Sobel 算子。
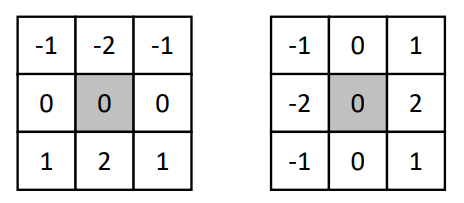
我们可以使用卷积来进行分别计算,最后合并两个方向的结果。不过需要注意的是,卷积中需要关闭 saturate 参数使得最终结果取绝对值。
另外,std 滤镜中也单独实现了 Sobel 算子,可以使用 std.Sobel 来调用。
Laplace算子
Sobel 算子是通过一阶偏导来计算的,事实上我们也可以通过二阶偏导来检测变化。
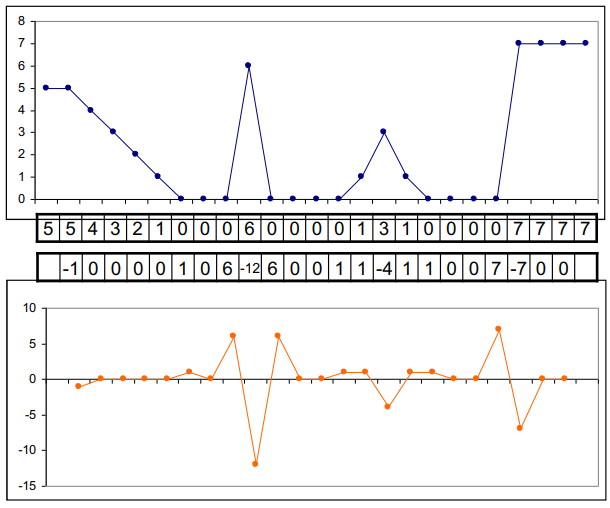
在二维空间上,类似的概念是 Laplace 算子。
因此我们有 Laplace 算子:
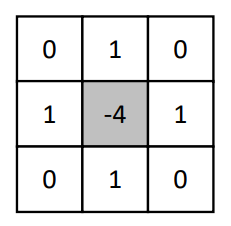
考虑到邻域,还有另外一种变体。
同样,我们可以使用卷积来进行实现。
3. TCanny滤镜
上面的算子虽然非常有效,但是它们是不可调节的。日常做番,我们更希望有一种能够调节强度的边缘检测方法,这主要通过 tcanny.TCanny 滤镜实现。
TCanny 是 VS 中功能最丰富的单一 edge mask 生成器。它有很多参数,我们现在先直接用它,在介绍了基础的 masktools 后会回过头来介绍它。
(1). 基本用法
先找一个比较干净的源,来看看 tcanny 会输出什么图像。
mask = core.tcanny.TCanny(src8, sigma=1.5, planes=[0])
mask = core.std.Expr(mask, ['', '128', '128'])
我们先看一个平面的 mask,第二行把色度平面设置为中间值,方便观察。
观察结果画面,观察 mask 出现的位置,有没有漏掉的线条。
再试试把 sigma 数值调大/调小,mask 会有什么变化。
sigma 调大,敏感度降低,mask 中平行线条的间距变宽。
敏感度高—>低的调节 线条的 TCanny 会是两条线->一条线->没有线。
大家再试试给源加点噪声,看看 mask 会有什么变化。
src8 = core.grain.Add(src8, var=30.0, seed=0)
会产生很多蛛网状的纹理。
tcanny 的 sigma 这个参数,在设计时就是用来消除这些噪声的影响的。
不过今天我们已经有丰富的降噪滤镜,它在今天的主要意义是去除一些小尺寸的纹理,使滤镜只关注主要线条。
(2). mask后处理
很多时候,生成的 mask 并不能达到我们想要的效果。
像前面那样,tcanny 生成的 mask 是中空的,即使是一条线的情况,它也太细了。
在 masktools 里有丰富的处理 mask 的滤镜,先来解决中空问题。
我们需要找到一种方法来填补 mask 中间部分。
std.Maximum 这个函数的操作是,把画面的每一个像素替换为 3x3 邻域内的最大值。
我们来看看它对于 mask 的性质:
- 如果一个像素本身是 mask (数值255),那处理后它还是 mask。
- 如果像素不是 mask,但它隔壁有个像素是 mask,那么处理后,这个像素也会变成 mask。
- 如果一个像素不是 mask,它隔壁也没有像素是 mask,那处理后这个像素依然不是 mask。
根据这些性质,我们可以推断出,std.Maximum 处理后的 mask 区域比处理前大,而且多出来的区域与原有 mask 区域是相连的。
可以想象,多次操作后,随着 mask 区域越来越大,双线条的空洞会缩小,最后消失。
对于单线条,这个操作也能让 mask 有效变宽。
与这个操作相反,std.Minimum 把画面的每一个像素替换为 3x3 邻域内的最小值,因此处理后的 mask 区域会比处理前小。
在需要填充空洞时,如果我们像这样先用 std.Maximum 把空洞填了,再用 std.Minimum 把 mask 区域缩回去。每一次滤镜调用都让 mask 的边缘扩张/收缩1个像素。当两者的执行次数相同时,最后输出的 mask 就既没有空洞,宽度又和有空洞时接近。
顺序是先几次 Maximum 再来几次 Minimum,而不是 Maximum, Minimum, Maximum, ...
回到前面噪声下的 tcanny 表现,有些噪声带来的 mask,在 Maximum 后会留下一块孤立的点。
这时,如果 Minimum 次数恰当,主要线条又足够宽,多次 Minimum 后就既保留了主要线条,又消除了噪点带来的 mask。
上面这些多次 Maximum/Minimum 的组合是最常用的 mask 操作,edge mask 相关每次都会用到。
在 AVS 中,std.Maximum 和 std.Minimum 分别叫做 Expand() 和 Inpand()。这也是 haf.mt_{expand, inpand}_multi 名字的由来。
std.Maximum 和 std.Minimum 都有个参数 coordinates,用来控制扩张/收缩的方向,默认是按方形扩张。
haf.mt_expand_multi 有个参数 mode 用来指定其他方向,有兴趣可以试试效果。
下一种场景是给 mask 挖洞。
比如 ringing 是出现在线条周围,如果我们直接用线条 mask,会框得太多了。
那(在 mask 足够宽后)先用 Minimum 收缩一下,再把两个 mask 相减之类的,空心 mask 就出来了。
TCanny 虽然也能出空心 mask,但比起 std.Maximum / std.Minimum 组合,它比较难控制 mask 空心的宽度。 haf.HQDeringmod 的 ringing mask 就是类似这种设计。
另外,std 里还有两个常用函数:std.Inflate() / std.Deflate()
inflate = Max(clip, RG(20))
deflate = Min(clip, RG(20))
这里 Max 就是逐点取最大值,由此我们知道,Inflate 其实就是一种 mask 的扩张,不过扩充出来的像素的值没有 std.Maximum 那么大,而是模糊了一点。
在使用二值 mask 中有时会用一下这个函数,模糊一下 mask 的边缘,避免 MaskedMerge 后画面改变太突兀。不直接使用模糊函数是希望原来的 mask 强度不降低。当然,有时我们扩张的足够宽,直接使用RG也是没问题的。
Deflate 同理,是一种强度更小的收缩。
(3). Hysteresis
在讲 TCanny 之前还有一个重要的 mask 处理滤镜:misc.Hysteresis,它通常用于消除 mask 中噪声带来的误判。
相比取两个 mask 的最小值,这个滤镜会多框一些区域。它的行为可以这样描述,对于第二个 mask 的每个连通分量,如果其中任何一个像素也在第一个 mask 中,那么整个连通分量都会保留到输出中。这里的连通分量是按照 3x3 的邻域定义的。
这么描述起来比较抽象,我们通过下面这个例子来看看它的效果。
mask_small = core.tcanny.TCanny(src8, sigma=3.0, planes=[0])
mask_big = core.tcanny.TCanny(src8, sigma=1.5, planes=[0])
mask = core.misc.Hysteresis(mask_small, mask_big, planes=[0])
使用 misc.Hysteresis 时需要注意参数顺序,通常是小的(mask 框的少的)在前,大的(mask 框的多的)在后。
比较时可以按 mask_small, mask, mask_big 顺序比较。
(4). TCanny生成mask
有了前面的积累,我们可以来讲 tcanny 了。
tcanny.TCanny 的参数格式是 tcanny.TCanny(clip clip[, float[] sigma=1.5, float[] sigma_v=sigma, float t_h=8.0, float t_l=1.0, int mode=0, int op=1, float gmmax=50.0, int opt=0, int[] planes=[0, 1, 2]])。
实际上,TCanny 不是类似前面 Sobel 之类的边缘检测算子,而是一套边缘检测的流程方法。
它的整体流程为:
- 高斯模糊
- 计算梯度,生成连续 mask
- 非极大值抑制(消除非线条 mask)
- 双阈值化
- Hysteresis
最终得到一个二值化的 edge mask,这也就是 TCanny 滤镜默认的 mode=0 的行为。
除了生成二值 mask,TCanny 也可以只做到第 2 步,生成一个连续 mask,这对应 mode=1。其生成的 mask 性质是图像越锐利,mask 数值越大。
和 mode=1 相关的主要参数有 sigma (sigma_v),op 和 gmmax。
sigma 是高斯滤波的力度,用于降噪和消除弱纹理。
op 是步骤 2 中使用的边缘检测算法,它们的不同之处在于对不同的线条方向的输出强度,以及抵抗噪声的能力等。我们常用的是 op=2,即前面介绍的 Sobel。
第三个参数 gmmax 只是个乘法,将得到的 mask 数值进行一定缩放。我们组里一般指定为 255。
需要注意的是,这一参数在新版 TCanny 里变为了更直观的 scale,直接将得到的 mask 乘以 scale 数值。
scale 与 gmmax 的换算关系为,scale = 255 / gmmax。
也就是 gmmax=255 时,恰好满足默认的 scale=1.0。
但有个问题是,以前的 gmmax 默认值是 50,如果你以前使用默认 gmmax,而现在仍然使用默认 scale,就会导致行为不一致。因此在使用旧脚本时,需要特别注意这一问题。
这个参数只影响生成连续 mask(mode=1),其他模式不受影响。
另外,VS-C 对于 TCanny 滤镜做了一些兼容性处理,现在可以同时支持 gmmax 和 scale 参数,因此你可以仍然使用祖传的 gmmax 参数。不过这里建议大家,无论使用哪个,都显式写出 gmmax=255 或者 scale=1.0。
通常 TCanny(mode=1) 生成的连续 mask 数值很小,可以后续接 Expr 放大,使用 Expr 就不限于乘以常数来放大了,比如做一个平方。
默认的 mode=0,除了前面的参数外,还可以控制 t_h,t_l。
TCanny 会根据这两个值,用 std.Binarize 生成两个二值化 mask,然后进行 misc.Hysteresis。
这种复杂做法可以减轻图像噪声带来的干扰,得到更高质量的 mask。
下面介绍一个调 t_h,t_l 参数的方法。
设计一个逐平面调参的辅助函数,它的输出图像中有 3 种可能值:0,中间值,最大值。
对于给定的参数:
- 最大值对应的像素一定会被 tcanny 当成 mask
- 最小值对应的像素一定不会被 tcanny 当成 mask
- 中间值对应的像素,如果它通过其他中间值与任一个最大值像素相连 (3x3),那么这些中间值像素也会被 tcanny 当成 mask
以下图为例,红圈这些线条最后会被当成 mask,蓝圈的不会。

各参数的调整方法是:
(t_h 对应 mask_small, t_l 对应 mask_big)
- 对于 t_h,尽量让目标线条里至少出现一个最大值像素,同时非线条区域没有最大值像素。这个值高一点比较好,这样噪声的影响会少一点
- 对于 t_l,尽量让目标线条附近都有中间值像素。如果前面 t_h 调得好,t_l 这个值调低一点,框多一点也没什么问题
如果只调这两个参数效果不好,可以考虑调 sigma 或者其他处理,比如通过外部滤镜进行降噪。
调完了把函数换回 tcanny 确认效果。